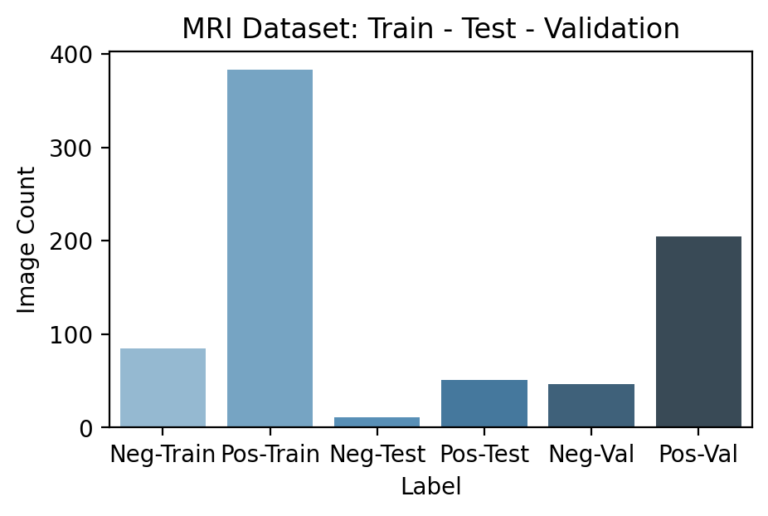The environment used to create and run the algorithms for the MRI Analyzer are on the public cloud- Amazon Web Services. We are running an EC2 instance and within that running the Deep Learning for Ubuntu operating system. Within that, the docker image is based on NVIDIA for PyTorch. The results and dataset are stored in an S3 bucket and we utilized Papermill to run our models.
The two key types of information contained for each patient was their medical images, used for the DNN models like ResNet, and other metadata, used for downstream tasks.
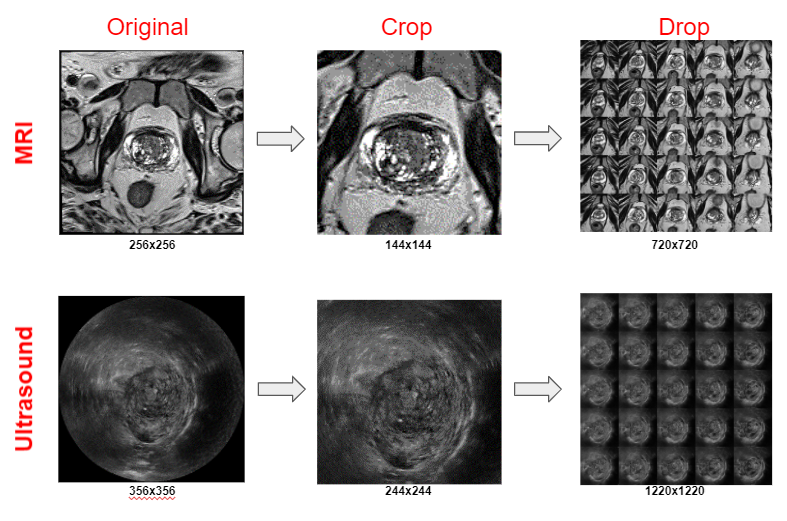
Once the transformations of the primary features, i.e. medical images, was decided upon they were implemented for the entire dataset. Given that these images were ~70 GB originally, efficient motivation and use of these transformations were required to add value while not creating unnecessary labor.
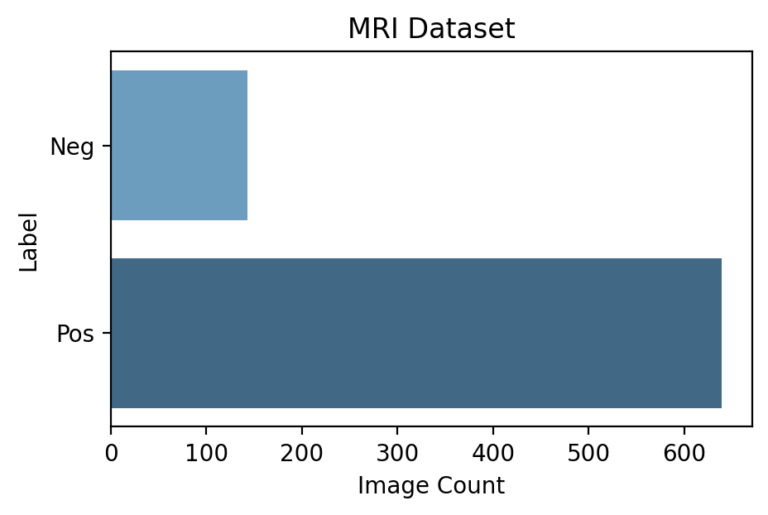
Each image is classified as Pos or Neg for cancer based on the following rule:
Biopsy Data → Cancer in Core %
If Cancer in Core % > 0 | Label = Pos
If Cancer in Core % = 0 | Label = Neg
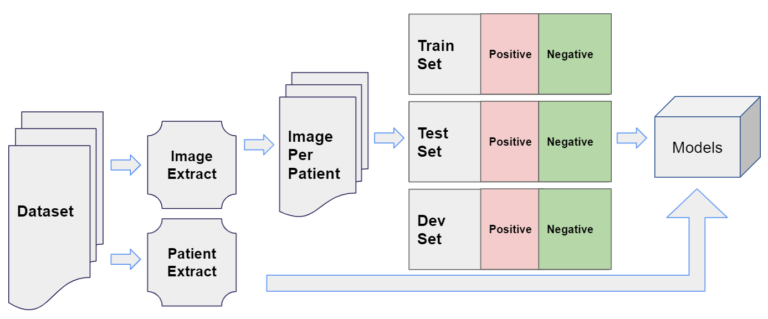
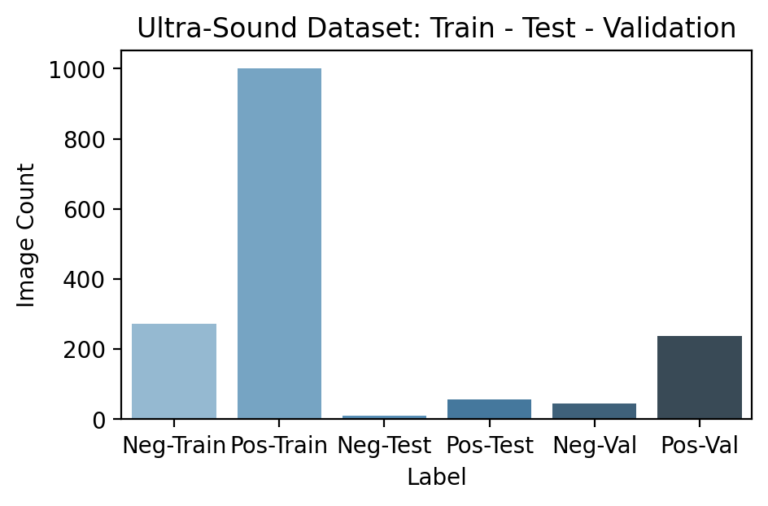
3. CREATE TRAIN, TEST, AND VALIDATION SET
Since the pipeline features certain models appearing after others, segmenting and ensuring no data leakage occurs during training is especially important. In particular, downstream models need not just a testing set that hasn’t been used earlier in the pipeline, but a unique training set as well. This is because any information seen by a previous model during its training would have been reflected in its final parameters, so that the predictions it passes further in the pipeline are incorrectly accurate. Because the previous DNN models are already large enough to “memorize” training examples, this led to especially obvious results if overlooked.
A variety of model architectures, hyperparameters, and data preparation techniques were trained and evaluated on to improve the DNN models’ performance. These include:
Use ResNet18/50
Size and resolution of image collages
Various LR, Weight Decay, and other optimization parameters
Various optimization algorithms
5. DEEP NEURAL NETWORK MODELS INfERence
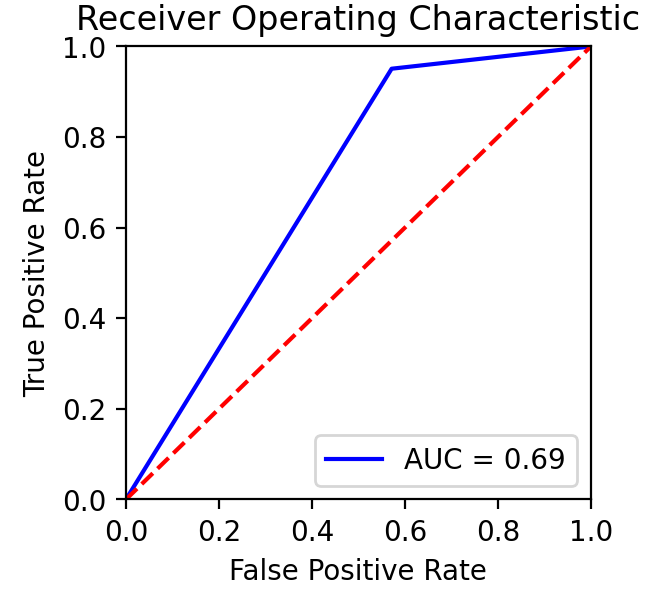
Based on team conversations with physicians, published literature, and general medical knowledge, it is expected that MRIs are much more capable of containing cancer relevant information than ultrasound images. In practice, MRIs are more highly detailed and used for guiding potential biopsies, while ultrasounds’ are used more for general location of the prostate among other nearby organs.
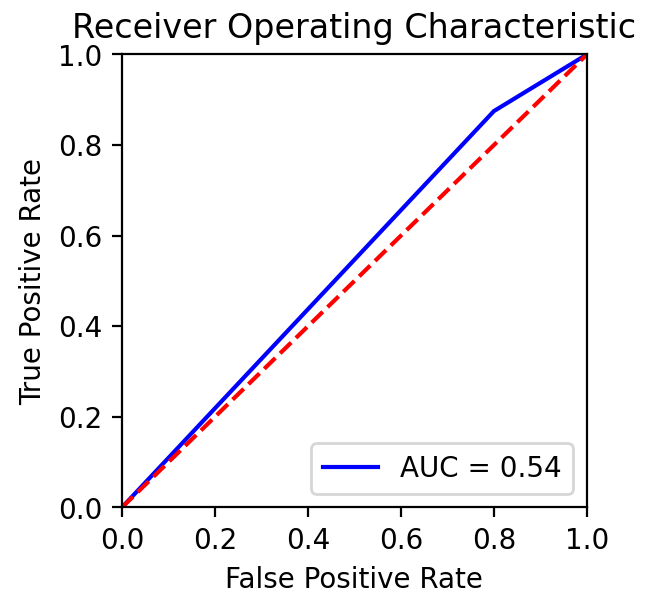
This was also found in the model results shown on the right, where the MRI DNN had much better performance than the Ultrasound DNN. In particular, the Ultrasound DNN was only slightly better than random. However, the combination of these two pieces of information in later steps was found to be more useful than either on their own. This reinforced the pipeline based approach of cancer diagnosis, over more traditional single models.
MRI
US
Previous
Next
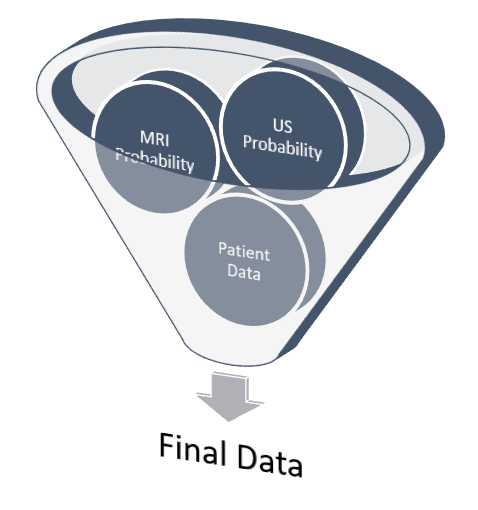
6. FINAL DATA
While some patients will have all attributes about themselves available for making a healthcare decision, others may not. In order to bridge the gap between a single model cancer classifier and a pipeline that is able to take advantage of different data sources, actions to take when a patient does not have all data fields must be decided upon and prepared for in advance.
This was accomplished in the pipeline by training and evaluating all individuals with the average dataset value for each variable for any which were missing. In total, about one fourth of the patients in the dataset had at least one missing value for at least one variable. Only the MRI and ultrasound results were found to be critical for classification and could not be substituted with the group average. Therefore, the final product is robust enough to classify patients with at least these attributes while producing the reported metrics below.
Several different supervised classifier models were considered to combine the MRI and ultrasound DNN model predictions with patient metadata in order to make the final cancer prediction.
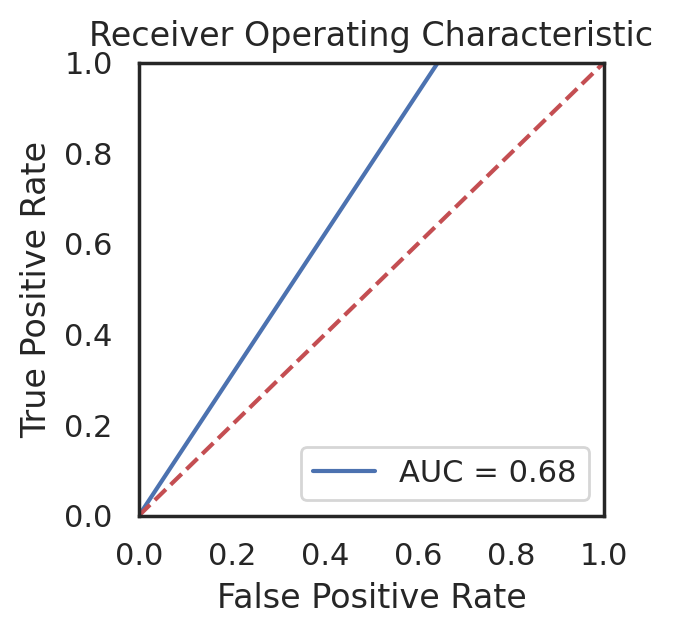
Ultimately, a Random Forest classifier was chosen not just because of its AUC metric, but just as importantly because of the types of errors it made. Shown in the ROC graph on the right, the model has a perfect true positive rate. This indicates that every patient who does have cancer is correctly classified by the model. In a healthcare setting, especially with a condition such as cancer, the consequences of a false negative far outweigh the consequences of a false positive. Therefore, while better AUC values were able to be achieved with other models or hyperparameters, this implementation was settled upon because of its better fit for the problem.
8. novelty - uncertainty Estimation
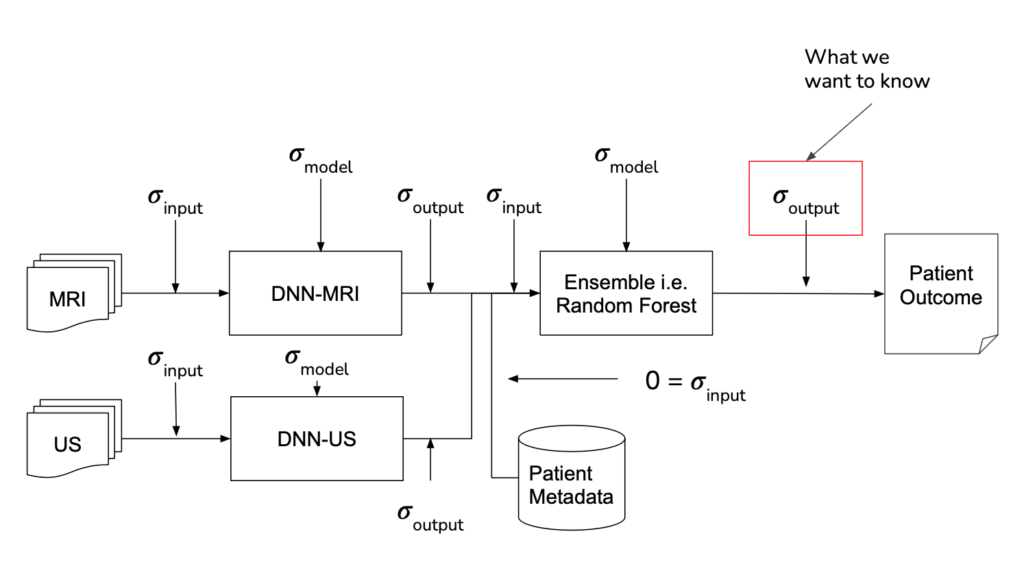
It is sometimes described that the difference between machine learning and classical statistics is that the former focuses on performance while the latter focuses on understanding. Following this notion, when working with human health it is important to not just make a correct prediction but also understand when ambiguity may exist for a specific patient. To include this, uncertainty estimation and propagation was included for each step of the pipeline, shown below, in order to gain this level of understanding.
To read more on this, continue to the Originality section next.